Graph Attention Deep Q-Network (GDQN)
This directory contains the implementation of the Graph Attention Deep Q-Network (GDQN) agent and related utilities.
Overview
The GDQN module is designed to provide a robust agent that selects actions in a graph environment based on Q-values; A variant of the Deep Q-Network. The architecture is shown below [1]
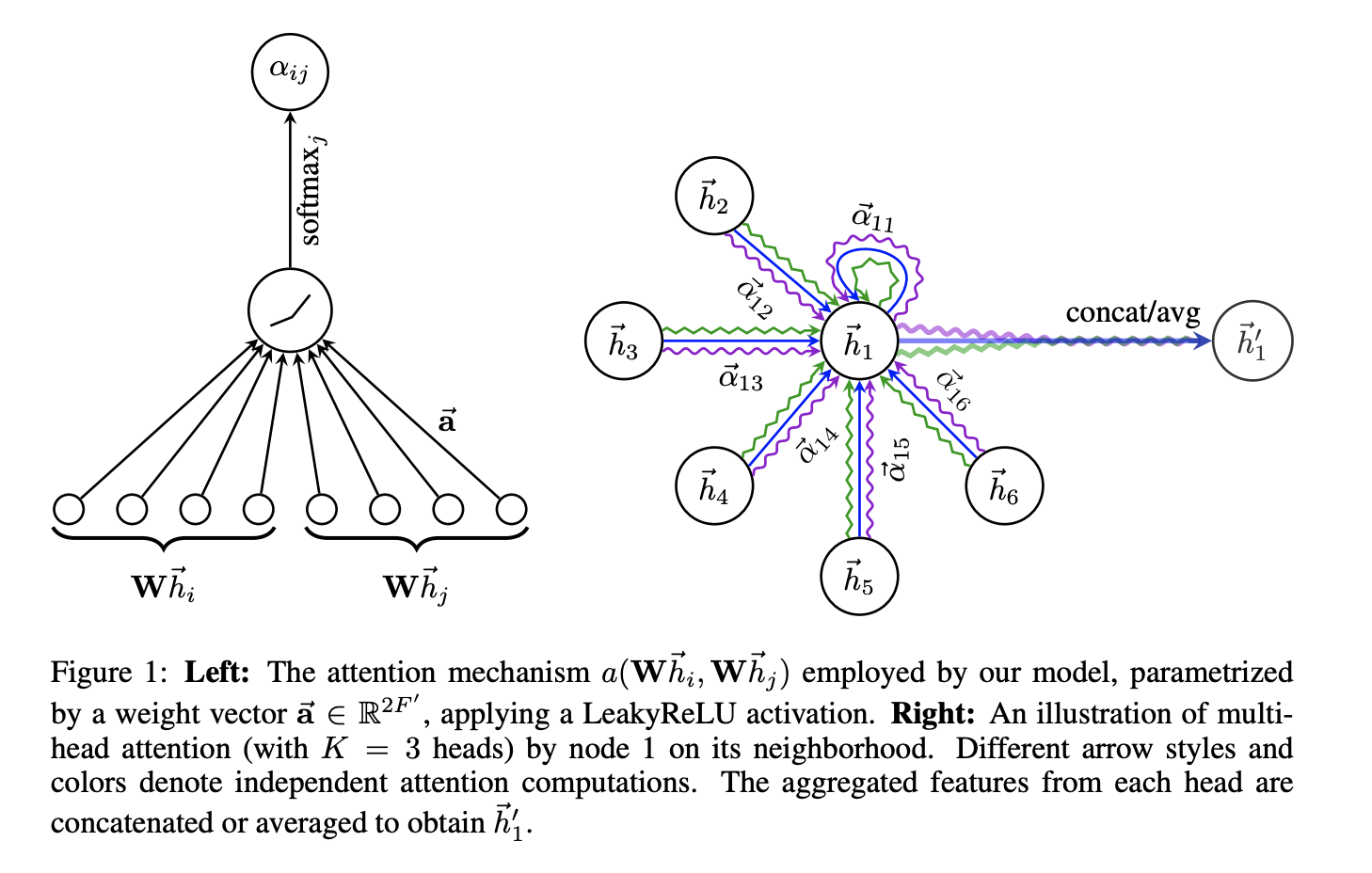
GAT Layer
-
Input - A set of node features (pos, group)
-
Output - A new set of node features A new set of node feautres
-
Weight Matrix is applied to every node
h = tf.matmul(input, W)
-
allows every node to attend every other node
-
Compute Attention Coefficient
-
Inject graph information by masked attention to compute for for in Neighborhood
e = leaky_relu(e)
adjacency_expanded = tf.cast(adjacency, tf.float32)
adjacency_expanded = tf.expand_dims(adjacency_expanded, axis=-1)
e = tf.where(adjacency_expanded > 0, e, -1e9 * tf.ones_like(e))- Normalize coefficients for easy comparison across all
ai_j = tf.nn.softmax(e, axis=2)- is either concatenated or averaged
h_prime = tf.reduce_sum(alpha_expanded * h_j_tiled, axis=2)
if self.concat:
#concat heads
h_prime = tf.reshape(h_prime, (batch_size, num_nodes, self.num_heads*self.out_dim))
else:
#Average heads
h_prime = tf.reduce_mean(h_prime, axis=2)Action Selection
- Initialize the environment using
env.reset()This will provide the initial state S0
- Then is passed into
agent.select_action(state)-
select_action()converts the state (node) into tuple- - tensor of node features
- - tensor of adjacent nodes
-
is then passed into a Q-network and returns a tensor of Q-values
-
The tensor of Q-values are mapped to their
node_idsand the node with the max Q-value is selected and returned to the agent
Train Step
After taking a action (step) the agent recieves
next_state, reward, done, info and is added to the ReplayBuffer and we update the state to the next state , and the reward is added to the total reward
-
Check Replay Buffer Length
train_step(batch)Check the replay buffer to ensure the buffer has atleast a batch of experiences stored. takes a random batch of the replay buffer
-
Sample Experiences
- For each state in the batch preprocess_state() is called which returns a tuple where the first element is and and is converted into a numPy array
-
Process States
- The target netowrk computes the Q-values for each next state. These values are later used to calculate the target for our Bellman update
-
Target Q-values & Bellman Update
- For each sample in the batch the target Q-value is computed
np.max(next_q.numpy(), axis=1)takes the maxium Q-value across all possible actions in the next state. Multiplying ensures that if the state was terminated, the future reward is
-
Forward Pass under GradientTape
- The current Q-values for the batch of states are computed by passing and through the Q-network Forward pass under GradientTape
-
Extracting Q-values for Taken Actions
-
The Q-values are extracted for taken actions. SInce the network outputs Q-values for all possible actions (for each state), we need to select the Q-value corresponding to the action that was actually taken.
-
tf.range(batch_size)creates a tensor with batch indices, which are stacked with the actions to form a tensor of indices -
tf.gather_ndextracts the Q-value at each (batch, action) pair
-
-
Loss Computation
- the mean squared error (MSE) is computed between the computed target Q-values and the Q-values for the actions taken.
-
Backpropagation and Optimization
- Gradients of the loss with respect to the Q-network's weights are computed then applied via the Adam optimizer to update the network parameters
-
Epsilon Decay
- The exploration rate is decayed to reduce exploration in favor of exploitation as training progesses.
Getting Started
-
Install Dependencies
Ensure you have installed the required dependencies for the project. This includes the setup.py file to ensure all modules can be imported.pip install -e . -
Run Training
from the base directory, use the provided training scripts to train your GDQN agent. Example:python RL/GDQN/agent.py
References
@misc{veličković2018graphattentionnetworks,
title={Graph Attention Networks},
author={Petar Veličković and Guillem Cucurull and Arantxa Casanova and Adriana Romero and Pietro Liò and Yoshua Bengio},
year={2018},
eprint={1710.10903},
archivePrefix={arXiv},
primaryClass={stat.ML},
url={https://arxiv.org/abs/1710.10903},
},